



Not All Backtests Are Created Equally
"If past history was all there was to the game, the richest people would be librarians" - Warren Buffett
Not All Backtests Are Created Equally
"If past history was all there was to the game, the richest people would be librarians" - Warren Buffett
Not all Backtests Are Created Equally | Reading Time: 7-10 minutes
The underpinning of today’s broad acceptance of index investing stems from the creation of the Efficient Markets Hypothesis (EMH) in the 1960’s. Rather than rely on fund managers, the EMH concluded that it was impossible to beat the market.
Although an elegant theory, however, the EMH is weakened by the rigid set of assumptions required for it to be true.
The adoption of EMH is the result of financial theorists suffering from “physics envy”. Unlike natural laws of the universe, the study of financial markets is a social science. As hedge fund manager George Soros remarked, in social systems, fallible human beings are not merely scientific observers but also active participants in the system. Human uncertainty is an impediment to the scientific method, and as a result, the EMH fails in real-world.
We see very simple contradictions to the idea of “efficient” markets. For example, take the Dow Jones Industrial Average, an index which tracks the largest 30 industrial companies in the United States. By analyzing data over the past six decades, investors discovered that if this index simply tracked the 50 stocks with the lowest price-to-sales ratios instead, it would be more than five times higher than it is today.
Philomath Investment Research strongly advocates for empirical finance. There are simple and systematic strategies that investors can use to outperform an index fund. With this in mind, it is important to note that not all strategies that counter the EMH are legitimate. Many historical anomalies lack robustness and are the product of “factor fishing”.
Take a look at the graph below. It highlights an investment strategy that performs well in a backtest, but fails to translate to the real-world. These results are from an academic study on the performance of 215 “alternative beta” funds recently launched by investment banks. The graph shows the median strategy. It produced strong risk-adjusted returns on paper (Sharpe Ratio of 1.42), however live performance turned out to be 75% worse (Sharpe ratio of just 0.36).
In terms of correcting backtest errors which commonly lead to questionable trading results, the low-hanging fruit are issues with common sense and testing design. Specifically, non-investment factors, survivor-biased data, lookahead inaccuracies, and investment scale can cause misleading simulation results.
- Non-Investment Factors – There is a well-known study of a financial academician who found that butter production in Bangladesh explained 75% of the movements of the S&P 500 index from 1983 to 1993. This study was of course intended to be a joke. In an era of analytics, it is easy to find relationships over certain time frames that are coincidental. In order for investment factors to be robust, they must be backed by a realistic economic reason why they exist. All of the factors tested by Philomath Investment Research – quality, value, momentum and low volatility – are derived from analysis of company financial statements and trading activity. Each one is supported by decades of peer-reviewed academic studies.
Survivor-Biased Data – For investment analysts, a simplistic backtest will use data for all the companies currently in the index. This issue with this is that it does not account for all the companies that have, over the years, merged, fell out of the index or went bankrupt. Philomath Investment Research eliminates this bias by using a point-in-time database which includes fundamentals for historical index constituents. This is courtesy of Portfolio123, which licenses data from Compustat (the primary database used by financial researchers).
Lookahead Inaccuracies – One of the issues with a point-in-time database is that the fundamentals are assumed to be available at that specific point in time. For example, for a company with a fiscal year end of December 31st, the database assumes that financial statements would be available the next day on January 1st. In practice, investment analysts know that financial results are typically reported with a lag of 6-8 weeks following the end of the period. Furthermore, companies can restate earnings to reflect organizational changes or different accounting treatments after their initial reporting of results. To ensure realistic backtestings, Philomath Investment Research relies on the initially-reported results through Compustat and lags the use of fundamental data in factor calculations by 12 weeks.
Investment Scale – In his book “What Works on Wall Street”, James O’Shaughnessy found that almost all the superior returns offered by small stocks come from micro-cap stocks with market capitalizations below $25 million. Given that these micro-cap stocks are at risk of going bust, the only way to achieve stellar returns was to invest in a basket of several hundred. To implement this strategy in the real-world, however, an investor would incur significant transaction costs due to illiquidity. In addition, in some cases naïve backtesting can permit a $100 million dollar investment in $25 million dollar company. Therefore, to maintain backtest integrity, Philomath Investment Research excludes micro-cap stocks from our investable universe.
Rigorous Statistical Testing
"I've never seen a bad backtest" - Dimitris Melas, Head of Research at MSCI
Rigorous Statistical Testing
"I've never seen a bad backtest" - Dimitris Melas, Head of Research at MSCI
Rigorous Statistical Testing | Reading Time: 10-15 minutes
As noted above, the contrast between financial theory and practice is driven by the fact that investing is a social study, not a natural science. There is an emotional element to buying and selling securities, and investing is therefore closer to the study of psychology than it is to a physics experiment. As a result, standard scientific testing needs to be adjusted when it comes to evaluating historical trading strategies.
In scientific circles, the two-sigma rule is nearly universal (if you are interested, here is a brief primer on statistical testing). When conducting a hypothesis test (for example looking to show the score for the treatment group is different from the control group) a test statistic (t-stat) greater than two implies significance. Skipping some of the mathematical details, if your t-stat is more than two in absolute terms, you are at least 95% sure that your treatment has had a verifiable effect.
Unfortunately, this standard has carried over to finance. There is a broad collection of published research that uses the two-sigma rule to promote “significant” investment factors or market anomalies. Many of these studies are most likely false.
Enter selection bias. Crucially, the two-sigma rule only holds for a single independent experiment. This is typically not the case in financial backtests, where several factors are tested within the same historical dataset. Through this battery of tests, it is certain that a researcher will eventually find a factor that seems to be statistically significant. However, as the number of tests rises, the likelihood of finding a false positive increases dramatically.
Ironically, we can look to the study of natural sciences to mitigate selection bias. In order to declare that the Higgs Boson particle, a game-changer in the field of physics, truly existed, scientists adopted a 5-sigma standard. This is also true in the study of genetics, where technicians require a t-stat over 5 in some cases to avoid false positives. In any situation where the number of trials is large, researchers need to avoid cherry-picking two-sigma tests in light of the many others that failed to be significant.
Backtest Period: April 1st, 1999 - March 31st, 2016. Annualized Alpha and Beta figures are relative to the Russell 3000 Index.
For quantitative investment researchers, there are three tools used to separate robust factors from those that are spurious. In the interest of transparency, above we present analysis on all of the factors tested by Philomath Investment Research.
This analysis shows the results of backtested portfolios from April 1st, 1999 to March 31st, 2016 (17 years). Each portfolio consists of selecting the top-ranking stocks according to the specific factor being tested. What is defined as “top-ranking” varies between factors, in some cases it is the highest scoring quartile and in others it is all stocks above the bottom decile. The portfolios are equally weighted and rebalanced annually. We measure alpha, or outperformance, relative to the Russell 3000 Index (the starting universe).
In the third column from the right, the results of the Holm method are presented for each factor. A green cell indicates that there is a 95% probability that the factor’s outperformance is statistically significant. A red cell means that the alpha generated by the backtest is less reliable. The Holm test considers the results from all the trials attempted, and thus, penalizes attempts to data-mine historical records.
An analyst begins by ranking all their backtested strategies from most significant (defined as having the lowest p-value or highest t-stat) to least significant. From here, you apply the formula to the right:
To obtain a 95% probability of outperformance, the level of testing significance is equal to 5%. Assuming a total of 27 trials, the Holm Hurdle for the 1st ranked backtest is:
In our testing, the factor with the highest alpha t-stat (lowest p-value) was the “ROIC_CFO” factor. Its p-value was 0.001. This factor is deemed significant by the Holm method because the actual p-value is lower than the hurdle. From here, we test the 2nd ranked backtest and compare it to the Holm hurdle. When we come across a backtest where the p-value fails to be lower than the hurdle, we reject it and all others with higher p-values.
The second method of ensuring statistical robustness is the BHY test. This acronym stands for the professors who developed it, Benjamini, Hochberg and Yekutieli. Like the Holm test, the BHY test is fairly straightforward to implement. We again rank all our trails, except this time we start with the least significant (highest p-value or lowest t-stat) and work towards the most significant.
c(M) is a cumulative function that equals 1 if the total number of trails is 1, (1+ ½) if we tested two trials and so on. For reference, the function equals 2.93 when we study 10 trials and approximates log(# of trials) in the case where we have many backtests.
In our research, the factor with one of the lowest levels of significance was “Shareholder Yield 3YR AVG”, with a p-value of 0.09. Assuming a 5% level of testing significance and a total number of 27 trials, the BHY Hurdle is:
Notice that the observed p-value is greater than the BHY Hurdle. In this case, we conclude that this factor’s outperformance is not statistically significant. We continue to test each factor in the ranks until we find the first one that has a p-value below the hurdle rate. At this point, the factor is accepted along with all others with lower p-values.
The final technique for separating strong historical factors from those that are questionable is to “haircut” the Sharpe ratio. Sharpe ratios, which measure risk-adjusted returns, have the potential to be inflated due to selection bias. In 2014 researchers proposed adjusting the ratio to take into account multiple testing. To adjust the Sharpe ratio, we multiply the observed p-value by the number of trials conducted. If the resulting product is less than the level of testing significance (0.05), the factor’s risk-adjusted performance is statistically significant.
For example, the p-value for the “EBITDA Yield” factor is 0.0018. Multiplying by the total number of backtests (27), we get 0.048. Given that this result is less than 0.05, we have greater confidence in this factor’s future outperformance.
As is highlighted in the graph, the Holm and BHY methods, along with the Sharpe ratio adjustment, can help determine which of your backtests are the most suitable for inclusion in an investment strategy. Of the 27 total factors Philomath Investment Research analyzed, just 7 passed all three of these statistical tests.
For more information on the statistical calculations presented on this page, please feel free to reach out to us at feedback@philomathinvest.com or refer to this academic paper.
Backtest Results
"Security Analysis has now reached the stage where it is ready for...evaluation by the use of established statistical tools" - Benjamin Graham
Backtest Results
"Security Analysis has now reached the stage where it is ready for...evaluation by the use of established statistical tools" - Benjamin Graham
Historical Backtest Performance
April 1st, 2004 - April 1st, 2016
Using a rules-based investment system, the historical Philomath portfolio held the 50 highest-ranked stocks in the US Equity universe. The portfolio was equally weighted and rebalanced annually.
Over the 12 years from April 1st, 2004 to March 31st, 2016, this portfolio generated a total return of 240%. This was more than 100% higher than the return of the passive index fund, representing an average annual outperformance of 3.44%.
While there is a lot to like about index funds, the key message of this website is that investors can do better. By adhering to a systematic, factor-based process, investors can build better portfolios and capitalize on inefficiencies in the stock market.
The backtest of our “thesis portfolio” serves as a proof-of-concept. An educated investor could have followed the trend and invested in a broad US Equity ETF such as the Russell 3000 Index Fund (Ticker: IWV). On the other hand, this investor could have relied on a handful of well-known and statistically robust factors to guide their stock selection.
Backtest Results | 12 years to March 31st, 2016
The portfolio essentially equalled the maximum drawdown (a measure of how far a portfolio falls from peak to bottom) of the index during the 2008 Financial crisis. With this in mind, on a risk-adjusted basis the portfolio still performed well. The Sharpe ratio, and its close cousin the Sortino ratio (which only measures downside deviations not total volatility) were far superior to the benchmark ETF.
It is both important and instructive to note that this outperformance was not entirely consistent. There were times when an investor in the Philomath portfolio could have underperformed the index by 10-12% annually. These situations were of course followed by periods of impressive outperformance, but the point is clear. In order for investors to realize the long-term benefits of the Philomath process, they need to be prepared for intervals of bleak relative results.
The historical backtest assumed 1.25% in round-trip transaction costs (1% trading commissions and 0.25% in market impact or slippage costs). Although this had some affect on performance, the trading drag was minimal given the portfolio’s average annual turnover of just 12.8%. This reflects the long-term, value bias inherent in the Philomath process. Of the 85 total transactions realized over the 12 year backtest, 62.4% of them turned out to be winning trades. All told, winning trades returned on average 97.4% compared to losing trades which declined on average by 45.4%. This win/loss ratio is better than the majority of active managers.
Philomath Investment Research was created with transparency in mind. We believe that factor-based portfolios are more efficient than index investing, and openly share our results.
Live Results
Live Results
Current Portfolio
Returns to December 31st, 2016. Inception Date: April 1st, 2016.
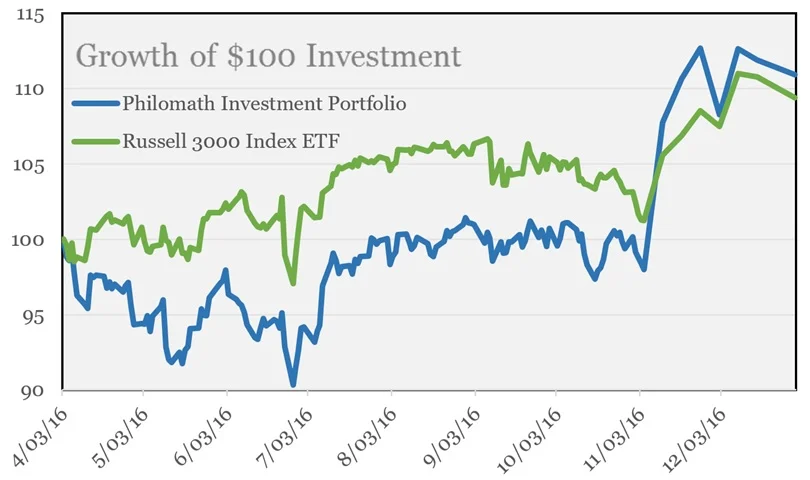
Returns to December 31st, 2016. Inception Date: April 1st, 2016.